Action-Free Reasoning for Policy Generalization

Abstract
End-to-end imitation learning offers a promising approach for training robot policies. However, generalizing to new settings—such as unseen scenes, tasks, and object instances—remains a significant challenge. Although large-scale robot demonstration datasets have shown potential for inducing generalization, they are resource-intensive to scale. In contrast, human video data is abundant and diverse, presenting an attractive alternative. Yet, these human-video datasets lack action labels, complicating their use in imitation learning. Existing methods attempt to extract grounded action representations (e.g., hand poses), but resulting policies struggle to bridge the embodiment gap between human and robot actions. We propose an alternative approach: leveraging language-based reasoning from human videos - essential for guiding robot actions - to train generalizable robot policies. Building on recent advances in reasoning-based policy architectures, we introduce Reasoning through Action-free Data (RAD). RAD learns from both robot demonstration data (with reasoning and action labels) and action-free human video data (with only reasoning labels). The robot data teaches the model to map reasoning to low-level actions, while the action-free data enhances reasoning capabilities. Additionally, we release a new dataset of 3,377 human-hand demonstrations compatible with the Bridge V2 benchmark. This dataset includes chain-of-thought reasoning annotations and hand-tracking data to help facilitate future work on reasoning-driven robot learning. Our experiments demonstrate that RAD enables effective transfer across the embodiment gap, allowing robots to perform tasks seen only in action-free data. Furthermore, scaling up action-free reasoning data significantly improves policy performance and generalization to novel tasks. These results highlight the promise of reasoning-driven learning from action-free datasets for advancing generalizable robot control.
Video
Human videos contain vast amounts of higher-level reasoning that guide robot action prediction. This reasoning information can be captured via language.

Task: Pick up the tiger. Plan: 1. Approach tiger; 2. Descend and grasp; 3. Lift and retract.
Subtask: Approach tiger. The tiger is on the desk, but other objects may be in the way.
Move: move left down.
Move Reason: Initial positioning to avoid collision with obstacles and start approaching the target from a direction to clear the keyboard
RAD learns new tasks from only human video data
Method

Experiments
We evaluate RAD across a variety of generalization tasks. These tasks comprise three main axes of generalization: (1) Compositional Generalization : In this axis, the objects, tasks, and scenes are all seen in pre-training data (Bridge V2 data), but not in those particular configurations. For example, pizza and salt both exist in Bridge V2, but salt is never placed on the pizza. (2) New Object Generalization: Unseen objects for known behaviors (e.g., "pick cup" to "pick plushie". (3) Scene Generalization : Generalizing to novel backgrounds and distractor objects for seen tasks; for example, picking up a known object with a pot in the background.
Cross-Embodiment Transfer
First, we assess if RAD can learn accurate reasonings and robot actions on new tasks that are present only in human video demonstrations.

RAD outperforms baselines where human video data was trained on, but no new robot data was provided. RAD-A is RAD trained only on human video data for the given axis of generalization. ECoT-GT is finetuned on the same data as RAD, but only using human hand locations (and not the full reasoning data)
ECoT reasoning

ECoT is unable to detect the milk carton and predicts the incorrect move.
RAD reasoning

RAD learns to identify the milk carton and chooses the correct move based solely on human video data.
RAD Rollouts
Compositional: Put the potato on the plate
New Scene: Pick up the milk
New Object: Pick up the cup
Generalization

RAD compared to ECoT for tasks contained in neither human or robot data. RAD shows improved performance across all three axes of generalization.
Compositional: Put the green bottle on the plate
New Scene: Put the carrot on the rack
New Object: Pick up the plushie
Cross-Environment Transfer
To truly leverage large-scale video data, generalist robot policies must learn from demonstrations in diverse scenes. Thus, we first train RAD with human video data in unseen environments to see how well it can incorporate this data, and then we compare its performance to RAD trained on in-distribution human video data (i.e., same environment for both human video and robot evaluation).
Data from outside target environment
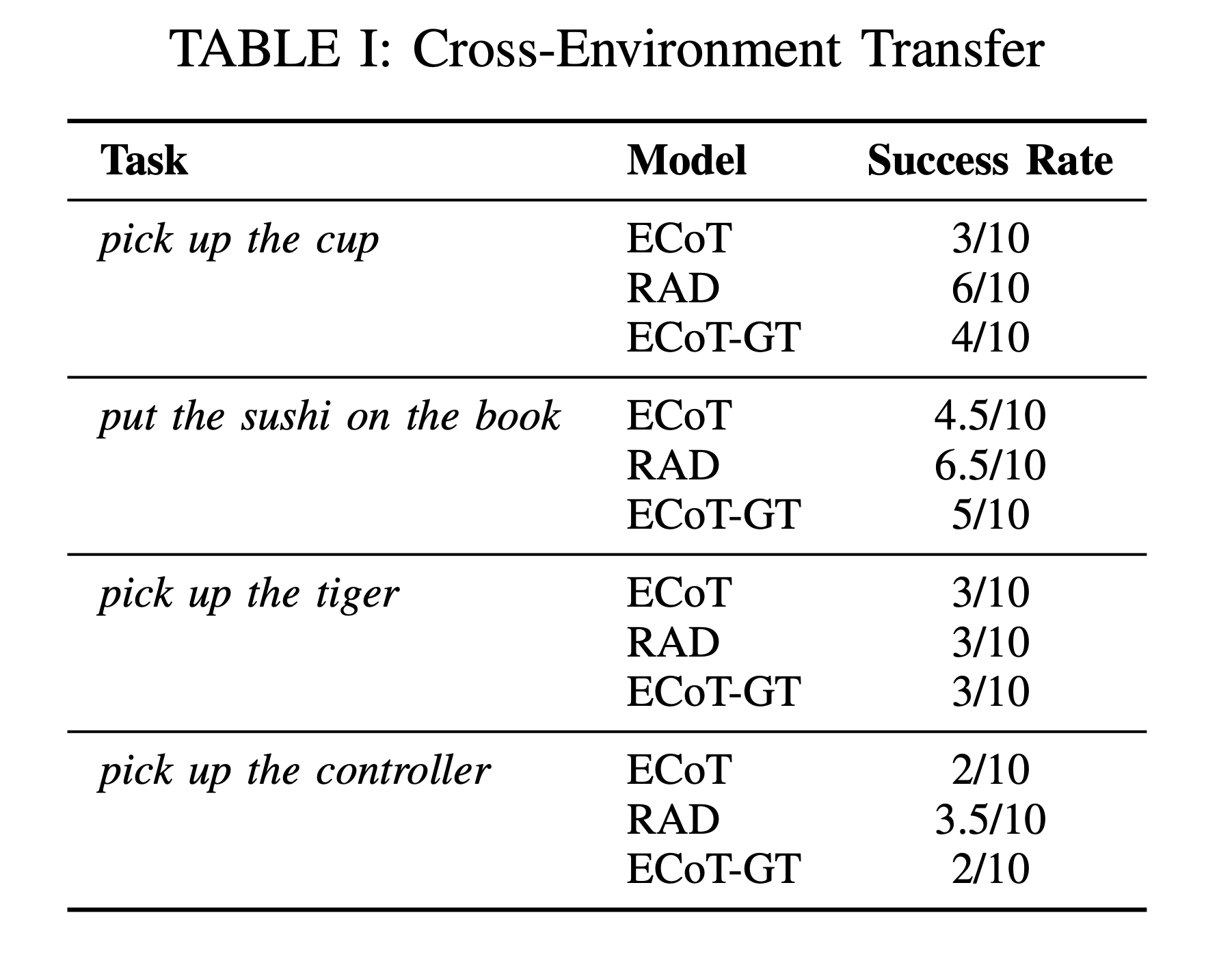
We collected data for four unseen tasks in a new tabletop setups (unseen in Bridge V2 data). Then, we evaluate models trained on this new enviroment data in the original Bridge Toy Sink environment. We find that models trained on this data outperform ECoT by 16% and ECoT-GT by 13%.
Scaling data collection
We assessed how RAD performance scales with increased data for the same tasks collected in-distribution (in the miniature Toy Sink setup) versus out-of-distribution (various real world kitchen and office environments). To do so, we collected 100 additional demos for the "pick up the tape" task in the Toy Sink setup. We also collected 250 out-of-domain demos for "pick up the tape" in novel environments such as real kitchens, countertops, and desks. Then, we trained RAD on two different data mixtures.

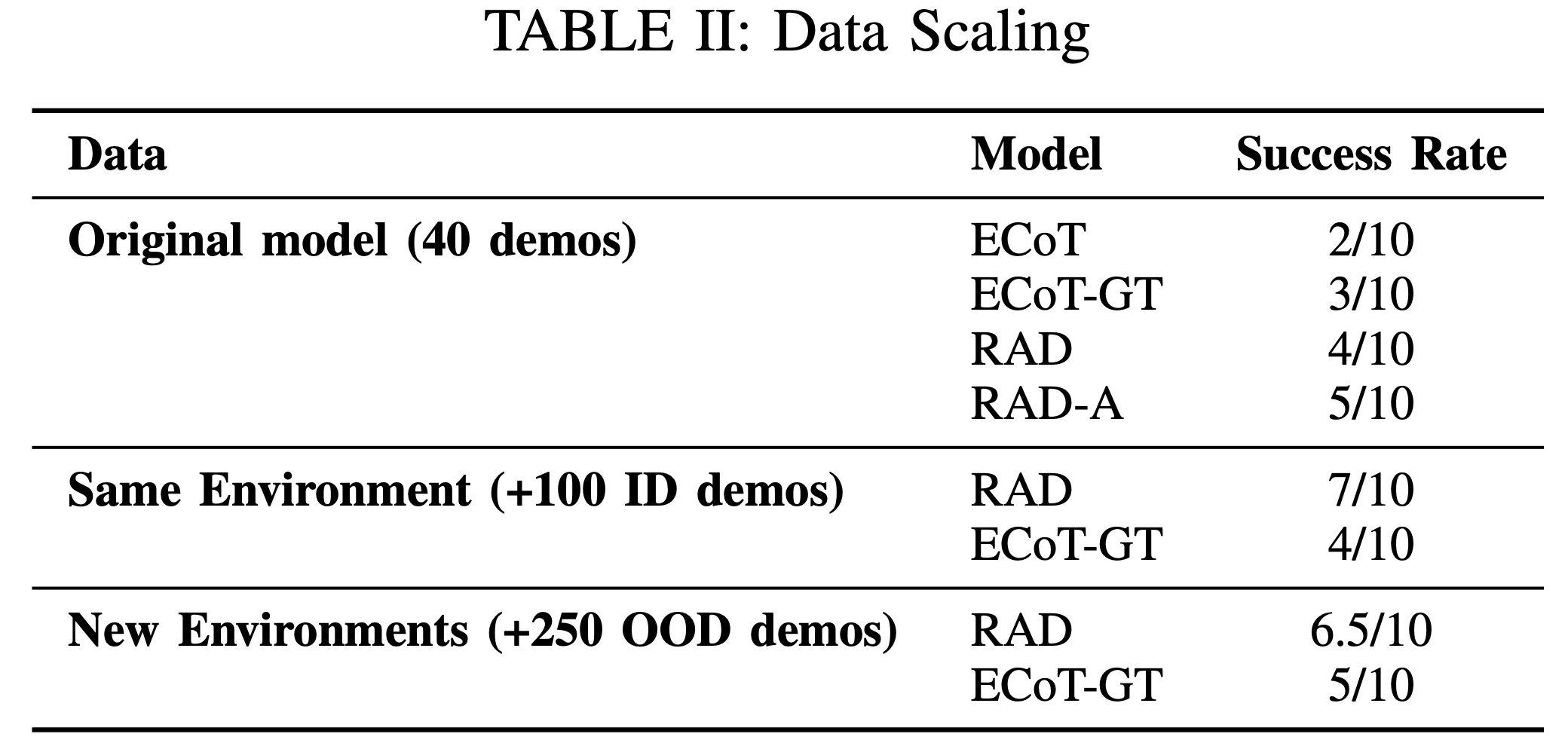
We find that RAD models trained on both in-domain (+30% success) and out-of-domain data (+25% success) show improved performance over the original model. This indicates RAD scales well with diverse training data.
Citation
Acknowledgements
We thank Priya Sundaresan and Juntao Ren for code for setting up HaMeR tracking. We thank Jonathan Yang, Satvik Sharma, Rahul Chand, and Priya Sundaresan for paper writing support. This work was supported by NSF #2006388 and #2125511, DARPA YFA Grant #W911NF2210214, ONR N00014-21-1-2298, Toyota Research Institute, and DARPA TIAMAT project.
The website template was borrowed from RT-H which was borrowed from Jon Barron.